![[로컬 AI 가이드] 내 PC의 한계를 끌어올리는 법: GPU 가속과 양자화(GGUF) 이해하기](https://evuelaimg.dothome.co.kr/blog/2026/03/img_69a544798eb98_1772438649.png)
지난 포스팅에서는 모델 이름 옆에 붙은 'B(매개변수)'를 레고 블록에 비유해 성능의 체급을 알아보았었다. 숫자가 클수록 똑똑하지만, 그만큼 내 PC가 감당해야 할 짐도 무거워진다는 결론이었다.
하지만 사용하다 보면 "내 그래픽카드 메모리(VRAM)는 한정되어 있는데, 더 크고 똑똑한 모델을 돌릴 방법은 없을까?" 혹은 "왜 내 AI는 대답 속도가 이렇게 느릴까?" 하는 의문이 생기기 마련이었다. 오늘은 이 고민을 해결해 줄 두 가지 핵심 열쇠인 GPU 가속과 양자화(Quantization)에 대해 상세히 기록해 보려 한다.
1. GPU 가속: 조립 도우미 투입하기 (GPU Offloading)
입문자들이 가장 많이 겪는 현상 중 하나가 "내 CPU도 좋은 건데 왜 AI는 느린가요?"라는 질문이었다. 결론부터 말하자면 AI 모델의 추론은 단순한 계산을 수천 개씩 동시에 처리해야 하기에 CPU보다는 GPU가 훨씬 유리했기 때문이다.
-
작동 원리: 모델의 연산 데이터를 일반 RAM이 아닌 그래픽카드의 전용 메모리(VRAM)에 올려 처리하는 방식이다. 수천 명의 보조 조립가인 GPU가 함께 달라붙는 셈이라 속도 차이가 비약적이었다.
-
LM Studio 설정: 우측
GPU Settings의GPU Offload슬라이더가 바로 이 '보조 조립가'를 얼마나 투입할지 결정하는 메뉴였다.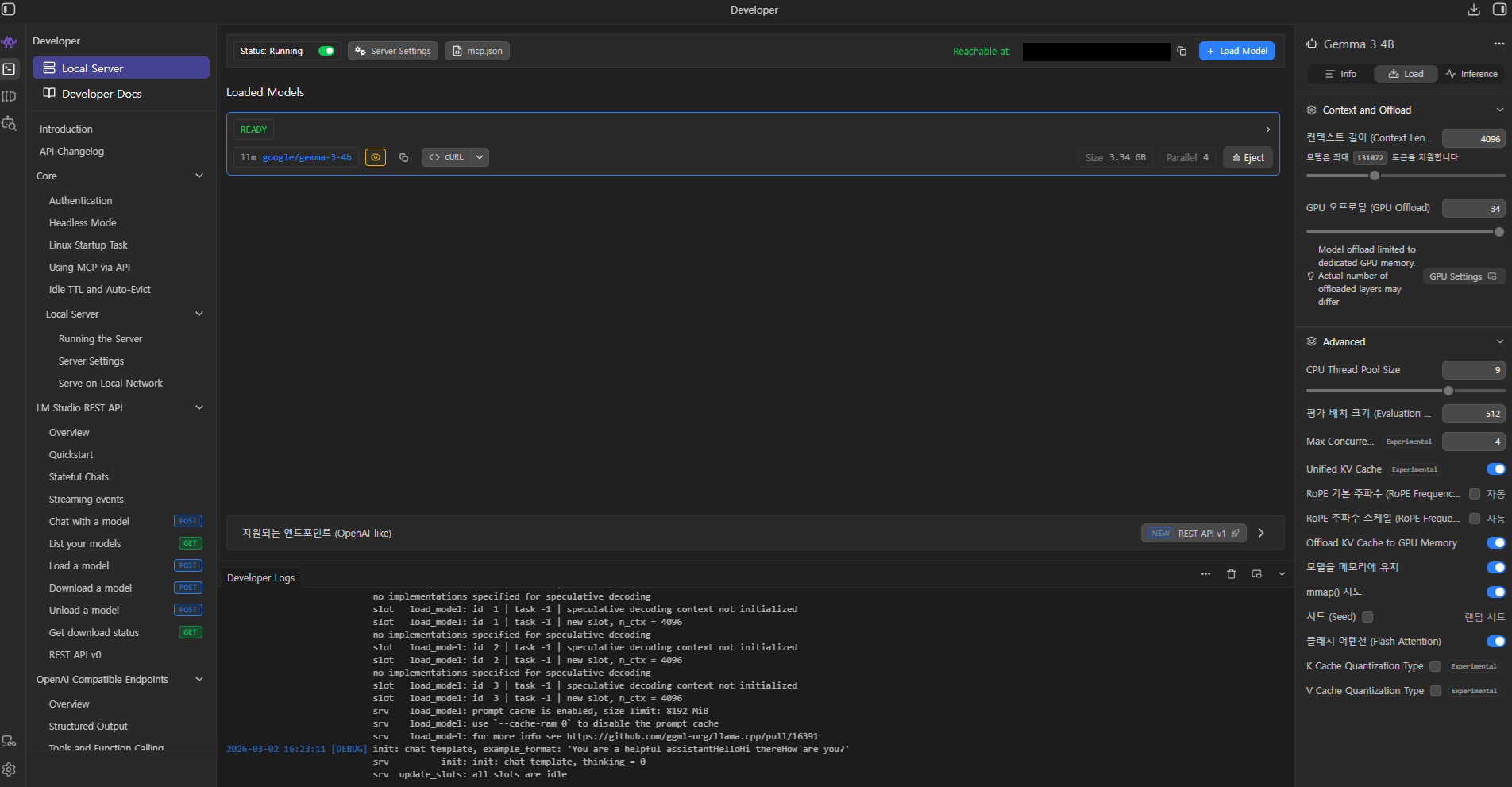
우측 메뉴를 보면 GPU 오프로딩이 있다. -
핵심 포인트: 모델의 모든 레이어(Layer)를 VRAM에 다 올릴 수만 있다면 대답 속도는 매우 빨라졌다. 만약 일부만 올린다면 나머지는 다시 CPU가 처리하게 되어 병목 현상이 발생하는 구조였다.
GPU 오프로딩 모두(full) 사용할때와 1개만 사용했을때의 차이는 아래와 같다.
초당 토큰이 높을 수록 더 빠르게 결과물이 나온다
채팅 질문 : "나에게 공포 테마의 소설을 1000자로 작성해줘"
- GPU 오프로딩 34 (풀로 올렸을 때)
초당 223.12 토큰
- GPU 오프로딩 1 (1개만 올렸을 때)
초당 27.53 토큰
2. 양자화(Quantization): 레고 블록의 크기 줄이기
내가 가진 책상(VRAM)은 좁은데, 꼭 거대한 성(대형 모델)을 만들고 싶을 때 사용하는 마법 같은 기술이 바로 양자화였다.
-
개념: 모델을 구성하는 데이터의 정밀도(bit)를 낮추는 기술이다. 고화질 4K 영상을 용량을 줄이기 위해 FHD로 압축하는 것과 비슷했다. 지능(화질)은 미세하게 떨어지지만, 용량(VRAM 점유)은 획기적으로 줄어들었다.
-
GGUF 형식: 로컬 환경에서 가장 많이 쓰이는 포맷으로, 파일 하나에 모델 정보가 압축되어 있어 관리가 편하고 사양에 맞춰 GPU와 CPU에 나눠 담기에 최적화되어 있다는 인상을 받았다.
허깅페이스 사이트에 들어가보면 GGUF 모델들을 확인해볼 수 있다.
3. GGUF 모델명 읽는 법 (Q4, Q8, K_M의 의미)
LM Studio에서 모델을 검색하면 나오는 Q4_K_M, Q8_0 같은 코드는 어떤 방식으로 압축되었는지를 나타내는 지표였다.
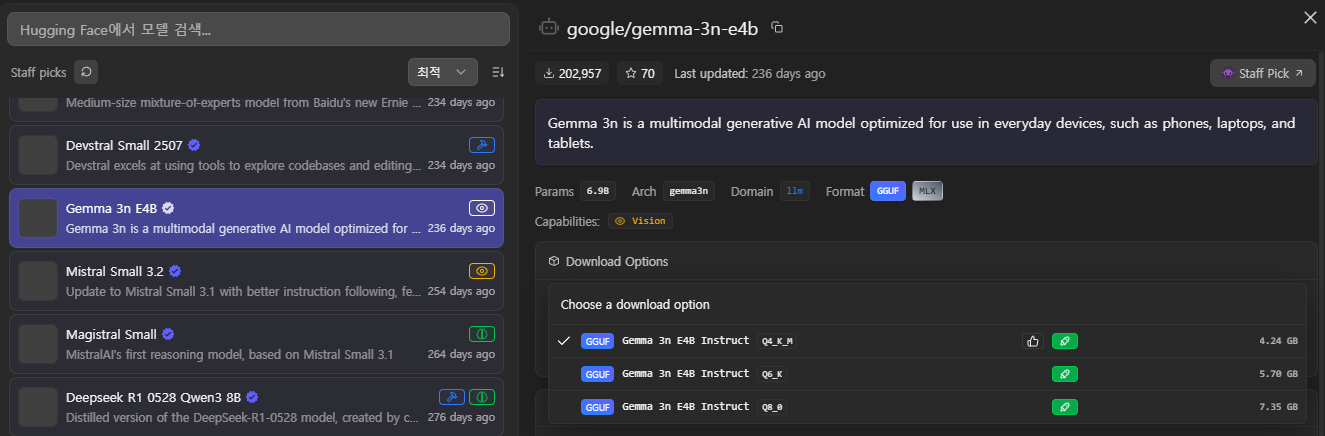
| 등급 (Quant) | 특징 (비유) | 추천 상황 |
| Q8_0 (8-bit) | 거의 무손실 고화질 | VRAM이 아주 넉넉하고 정교한 답변이 필요할 때 |
| Q4_K_M (4-bit) | 가장 대중적인 가성비 | 가장 추천하는 옵션. 지능과 속도의 균형이 매우 좋았다. |
| Q2_K (2-bit) | 화질 저하가 체감됨 | 모델이 너무 커서 실행조차 안 될 때 최후의 수단이었다. |
-
뒤에 붙는 S, M, L은 압축 시 얼마나 정교하게 데이터를 남길지를 의미하는데, 보통 M(Medium)이 가장 무난한 선택지로 느껴졌다.
4. 💡 나에게 맞는 최적의 선택지 찾기 (VRAM 계산)
결국 무조건 높은 비트(Q8)가 정답은 아니었다. 특히 대중적으로 많이 사용되는 8GB VRAM 환경에서는 모델의 체급(B)과 양자화(Q) 사이에서 최적의 타협점을 찾는 과정이 무엇보다 중요했다. 일반적인 사양을 고려해 모델을 고르는 기준을 다음과 같이 정리해 보았다.
-
자원 확인: 보통의 게이밍 PC가 갖춘 8GB의 비디오 메모리는 로컬 AI 입문용으로 가장 적절한 기준점이었다. 하지만 넉넉한 수치는 아니기에 '선택과 집중'이 필요했다.
-
모델 용량 계산 (8GB VRAM 기준 예시):
-
7B~8B 모델 (Q4_K_M): 약 5~6GB의 VRAM을 소모한다. 8GB 환경에서는 운영체제가 사용하는 기본 메모리를 제외하고도 모든 레이어를 GPU에 올릴 수 있었다. 덕분에 실시간 대화가 가능할 만큼 쾌적한 속도를 보여주었다.
-
14B 모델 (Q4_K_M): 약 10~12GB 이상의 VRAM이 필요하다. 8GB 장비로는 용량이 부족하여 일부 레이어가 CPU(RAM)로 넘어가게 된다. 이 경우 7B 모델보다 똑똑할 순 있지만, 답변 속도가 현저히 느려지는 것을 확인할 수 있었다.
-
-
체감 속도의 차이: 메모리 안에 모델 데이터가 "전부 올라가는가"가 속도의 핵심이었다. 8GB 사양에서 가장 지능적이면서도 스트레스 없이 사용 가능한 마지노선은 7B~9B 체급의 Q4~Q5 모델들이라는 결론을 얻었다.
맺으며
결국 로컬 AI의 핵심은 "제한된 내 PC 자원을 얼마나 효율적으로 분배하느냐"에 있었다.
무조건 큰 모델을 받기보다, 내 GPU 메모리에 딱 맞는 양자화 모델을 골랐을 때 비로소 스트레스 없는 AI 환경이 구축된다는 점을 다시 한번 배울 수 있었다.
![[로컬 AI 실전] 코드가 밖으로 새지 않는 100% 무료 코딩 어시스턴트 구축하기 (VS Code + Continue)](https://evuelaimg.dothome.co.kr/blog/2026/04/img_69d067df1eec9_1775265759.png)
![[로컬 AI 가이드] 내 AI를 200% 똑똑하게 만드는 법: 프롬프트와 파라미터 최적화](https://evuelaimg.dothome.co.kr/blog/2026/03/img_69a941e13007e_1772700129.png)
![[로컬 AI 가이드] AI의 기억력을 결정하는 두 열쇠: 토큰(Token)과 컨텍스트(Context) 이해하기](https://evuelaimg.dothome.co.kr/blog/2026/03/img_69a7af6e027e3_1772597102.png)
댓글 0개